AI, która uczy AI. Uczenie jeszcze głębsze, czyli hipersieć
Kolejne generacje sieci neuronowych są jeszcze bardziej spragnione danych i mocy obliczeniowej. Ich szkolenie wymaga starannego dostrajania wartości milionów, a niekiedy nawet miliardów parametrów charakteryzujących te sieci, reprezentujących siłę połączeń między sztucznymi neuronami. Celem jest znalezienie dla nich dążących do ideału wartości, co nazywamy optymalizacją. Szkolenie sieci nie jest łatwe, może trwać dni, tygodnie, a nawet miesiące.

Jednak to może się wkrótce zmienić. Boris Knyazev (1) z kanadyjskiego Uniwersytetu Guelph i jego współpracownicy zaprojektowali i wyszkolili "hipersieć", będącą swoistą siecią nadrzędną w stosunku do innych sieci neuronowych, mającą potencjał, by przyspieszyć proces uczenia. Działa ona w ten sposób, że gdy dostajemy nową, niewyszkoloną głęboką sieć neuronową przeznaczoną do wykonania jakiegoś zadania, hipersieć potrafi przewidzieć dla niej parametry w ułamku sekundy.
Teoretycznie może to doprowadzić do sytuacji, że szkolenie nie będzie konieczne, ale to na razie mglista perspektywa. Na razie hipersieci radzą sobie zaskakująco dobrze w określonych warunkach. Jeśli uda się rozwiązać pewne problemy i ograniczenia, to być może otworzy nową erę w uczeniu maszynowym.
Sieć matka wzorem dla kandydatek
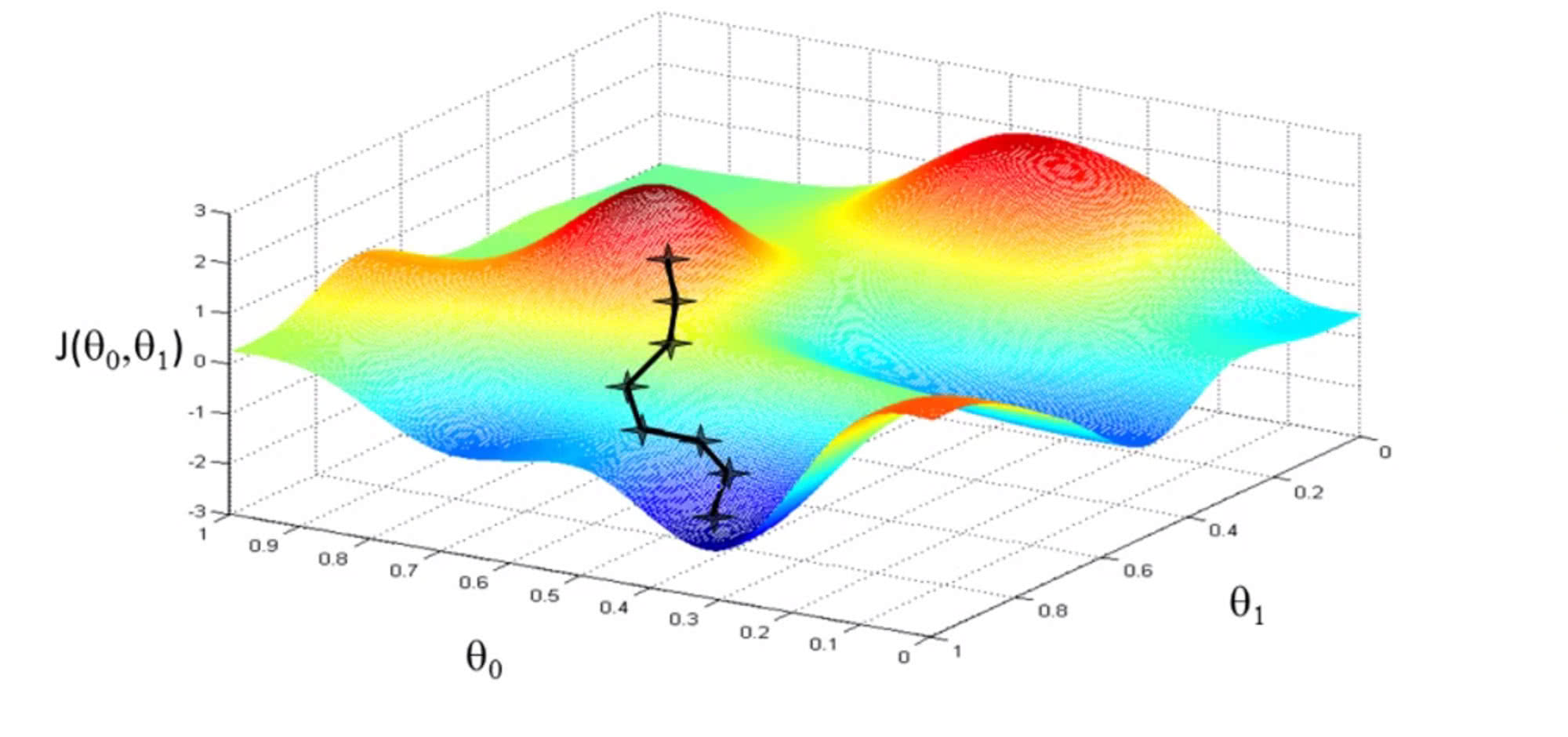
Obecnie najlepszymi metodami szkolenia i optymalizacji głębokich sieci neuronowych są warianty techniki zwanej stochastycznym zstępowaniem gradientowym (SGD). Proces uczenia polega na minimalizowaniu błędów, jakie sieć popełnia w określonym zadaniu, na przykład w rozpoznawaniu obrazów. Algorytm SGD przetwarza dużą liczbę oznakowanych danych, aby dostosować parametry sieci i zmniejszyć liczbę błędów. Zstępowanie gradientowe to powtarzalny proces przechodzenia od wysokich wartości funkcji straty do wartości minimalnej, która reprezentuje wystarczająco dobre (lub czasami nawet najlepsze) wartości parametrów (2).
Technika ta działa jednak tylko wtedy, gdy sieć jest już zoptymalizowana. Aby zbudować wstępną sieć neuronową, składającą się zwykle z wielu warstw sztucznych neuronów prowadzących od wejścia do wyjścia, inżynierowie muszą polegać na intuicji i regułach. Architektury, które tworzą, mogą się różnić pod względem liczby warstw neuronów, liczby neuronów na warstwę itd.
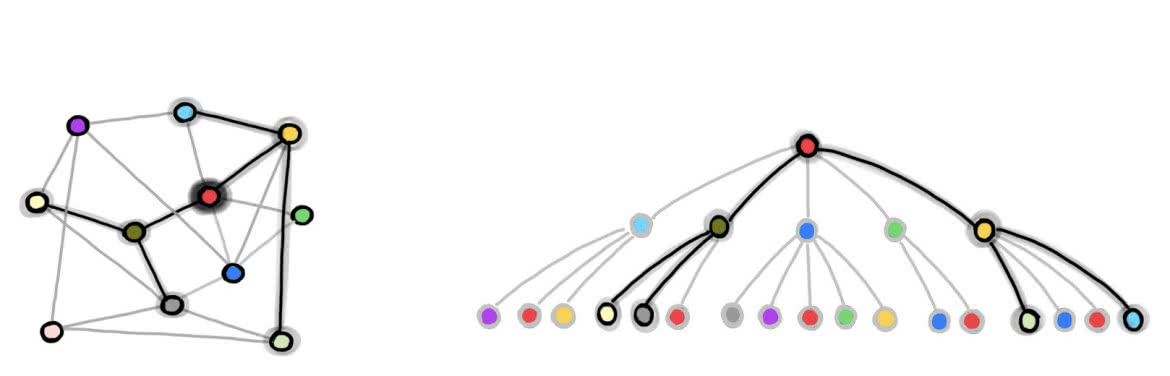
Teoretycznie można zacząć od wielu architektur, a następnie zoptymalizować każdą z nich i wybrać najlepszą. Ale to zajmuje sporo czasu i nie jest zbyt ekonomicznym podejściem. Dlatego w 2018 roku Mengye Ren z Uniwersytetu i jego zespół, spróbowali innego podejścia. Zaprojektowali coś, co nazwali hipersiecią grafową (GHN), aby znaleźć najlepszą architekturę głębokiej sieci neuronowej do rozwiązania jakiegoś zadania, biorąc pod uwagę zestaw architektur kandydujących. Nazwa nawiązuje do faktu, że architektura głębokiej sieci neuronowej może być postrzegana jako graf matematyczny - zbiór punktów, czyli węzłów, połączonych liniami. Węzły reprezentują moduły obliczeniowe (zwykle całą warstwę sieci neuronowej), a linie przedstawiają sposób, w jaki te moduły są ze sobą połączone (3).
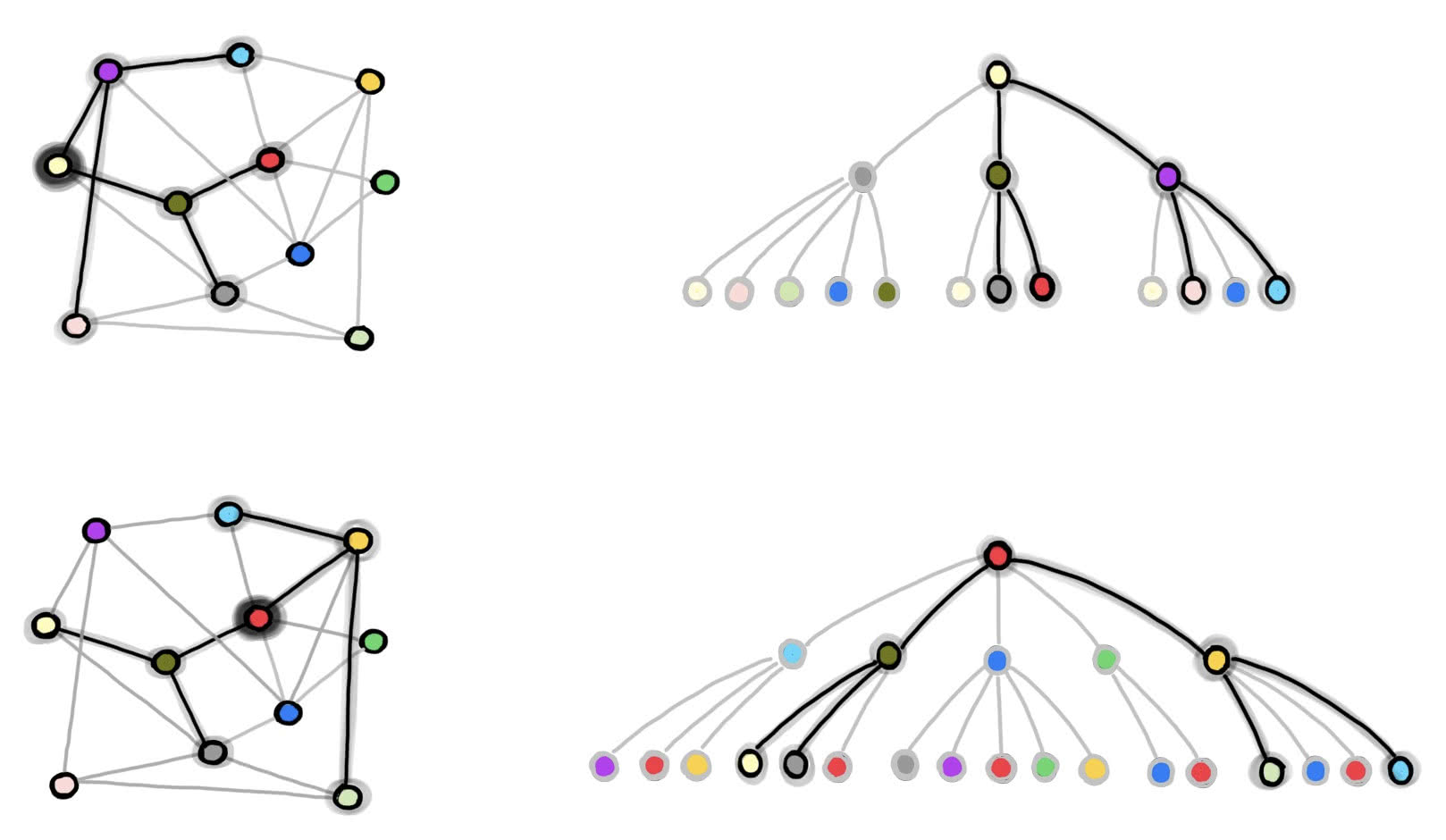
Hipersieć grafowa zaczyna od architektury, która wymaga optymalizacji (nazywamy ją kandydatką). Następnie stara się przewidzieć idealne parametry dla siebie. Następnie zespół ustawia parametry rzeczywistej sieci neuronowej na przewidywane wartości i testuje ją na danym zadaniu. Zespół Rena wykazał, że metodę tę można wykorzystać do klasyfikacji kandydujących architektur i wyboru najlepszej.
Kiedy Knyazev postanowili ten model rozwinąć. Pokazują, jak wykorzystać GHN nie tylko do znalezienia najlepszej architektury z pewnego zbioru przykładów, ale także do przewidzenia parametrów najlepszej sieci, tak aby osiągała ona dobre wyniki w sposób absolutny i uniwersalny. Nazwali swoją hipersieć GHN-2 i udoskonalili dwa ważne elementy hipersieci grafowej zbudowanej przez Rena i współpracowników.
Każdy węzeł grafu tej sieci koduje informacje o podzbiorze neuronów, które wykonują pewien określony typ przetwarzania. Linie grafu przedstawiają przepływ informacji od węzła do węzła, od wejścia do wyjścia. Pomysłem, z którego skorzystał zespół Knyazeva, była metoda uczenia hipersieci w celu tworzenia przewidywań dla nowych, kandydujących architektur. Do tego potrzebne są dwie inne sieci neuronowe. Pierwsza z nich umożliwia wykonywanie obliczeń na oryginalnym grafie kandydata, co skutkuje aktualizacjami informacji przypisanych do każdego węzła, a druga przyjmuje zaktualizowane węzły jako dane wejściowe i przewiduje parametry dla odpowiednich jednostek obliczeniowych kandydującej sieci neuronowej. Te dwie sieci mają również swoje własne parametry, które muszą zostać zoptymalizowane, aby hipersieć mogła poprawnie przewidywać wartości parametrów.
Knyazev i współpracownicy udoskonalili tę metodę. Na początek zidentyfikowali piętnaście typów węzłów, które można mieszać i dopasowywać, aby zbudować niemal każdą nowoczesną głęboką sieć neuronową. Dokonali również kilku ulepszeń w celu zwiększenia dokładności przewidywań. Aby mieć pewność, że GHN-2 nauczy się przewidywać parametry dla szerokiego zakresu architektur sieci neuronowych, Knyazev i współpracownicy stworzyli unikatowy zbiór danych zawierający milion możliwych architektur. "By wyszkolić nasz model, stworzyliśmy losowe architektury, tak różnorodne, jak to tylko możliwe", wyjaśnia w publikacji Knyazev. W rezultacie, zdolności przewidywania GHN-2 pozwalają na dobre generalizowanie wyników dla nieznanych architektur docelowych.
Prawdziwym testem było oczywiście zastosowanie GHN-2 w praktyce. Gdy Knyazev i jego zespół wyszkolili go do przewidywania parametrów dla danego zadania, takiego jak klasyfikowanie obrazów w danym zbiorze danych, sprawdzili jego zdolność do przewidywania parametrów dla dowolnej losowo wybranej architektury. Dysponując w pełni wyszkoloną GHN-2, zespół był w stanie przewidzieć parametry pięciuset wcześniej nieznanych, losowych architektur sieci docelowych. Następnie te pięćset sieci, których parametry ustawiono na wartości przewidywane, porównano z tymi samymi sieciami szkolonymi za pomocą tradycyjnego modelu stochastycznego zstępowania gradientowego. Nowe hipersieci czasami radziły sobie nawet lepiej, choć część wyników była niejednoznaczna.
W przypadku zestawu obrazów znanego jako CIFAR-10, średnia dokładność GHN-2 dla architektur typu indistribution wyniosła 66,9 proc., co było wynikiem zbliżonym do średniej dokładności 69,2 proc. uzyskanej przez sieci wyszkolone przy użyciu 2500 iteracji SGD.
W przypadku architektur o strukturze nierozproszonej, GHN-2 poradziła sobie zaskakująco dobrze, osiągając dokładność około 60 proc. GHN-2 nie poradziła sobie tak dobrze z ImageNetem, znacznie większym zbiorem danych: Przeciętna dokładność wynosiła tylko 27,2 proc. Mimo to wypada korzystnie w porównaniu ze średnią dokładnością 25,6 proc. dla tych samych sieci wytrenowanych przy użyciu pięciu tysięcy kroków SGD. Oczywiście, używając większej liczby iteracji SGD, można w końcu, przy znacznych kosztach, osiągnąć dokładność 95 proc. Co najistotniejsze, GHN-2 dokonała przewidywań dla sieci ImageNet w czasie krótszym niż sekunda, podczas gdy użycie SGD do uzyskania tej samej wydajności, co przewidywane parametry, zajęło średnio dziesięć tysięcy razy więcej czasu na procesorze graficznym.
A kiedy GHN-2 znajdzie najlepszą sieć neuronową dla danego zadania spośród próbek architektur, a ta najlepsza opcja nie jest wystarczająco dobra, to przynajmniej zwycięzca jest teraz częściowo przeszkolony i może być dalej optymalizowany. Zamiast uruchamiać SGD na sieci z losowymi wartościami jej parametrów, można wykorzystać przewidywania GHN-2 jako punkt wyjścia. Mamy wówczas siec wstępnie przeszkoloną.
Czarna skrzynka do prześwietlania innych czarnych skrzynek
Pomimo obiecujących wyników, Knyazev uważa, że środowisko zajmujące się uczeniem maszynowym będzie mieć opory wobec hipersieci grafowych. Porównuje to do oporu, z jakim spotykały się głębokie sieci neuronowe przed rokiem 2012. Wówczas praktycy uczenia maszynowego woleli algorytmy projektowane ręcznie niż tajemnicze głębokie sieci. Potem, gdy masywne głębokie sieci uczone na ogromnych ilościach danych zaczęły osiągać lepsze wyniki niż tradycyjne algorytmy, sytuacja zmieniła się.
W przyszłości hipersieci grafowe będą uczone na bardziej zróżnicowanych architekturach i w różnych typach zadań (np. rozpoznawanie obrazów, rozpoznawanie mowy i przetwarzanie języka naturalnego). Wtedy przewidywanie będzie mogło być uzależnione zarówno od architektury docelowej, jak i od konkretnego zadania.
Wprawdzie wielu ekspertów widzi w GHN-2 kolejną czarną skrzynkę działającą podobnie jak inne głębokie sieci neuronowe, nieprzejrzyście, to jednak, jak zwracają uwagę twórcy, potrafi generalizować, czyli może dokonywać rozsądnych przewidywań parametrów dla niewidocznych, a nawet nierozpowszechnionych architektur sieciowych. Teoretycznie więc, jako narzędzie do rozpoznawania wzorców, może być pomocą dla tych, którzy chcą przeniknąć mechanizmy działania AI.
Mirosław Usidus






